Web Architecture
Ezra Cooper
University of Edinburgh
The Idea
- Web protocols are built on principles that permit scale
and open-ended uses.
- Two key ideas:
- "Resources" as fundamental units.
- Uniform resource identification: URIs
Sources—Whatchu talkin' bout, Willis?
- "Architecture of the World Wide Web"
http://www.w3.org/TR/webarch/
"Web Architecture from 50,000 Feet"
- Architectural Styles and the Design of Network-based
Software Architectures (R. Fielding, PhD Thesis 2000)
- My experience making web apps, working with Atompub IETF
working group
What's a resource?
- Anything identified by a URI.
What's a resource?
- Anything identified by a URI.
- Could assign the URI
http://ietf.org/cities/edinburgh to Edinburgh itself.
What's a resource?
- Anything identified by a URI.
- Could assign the URI
http://ietf.org/cities/edinburgh to Edinburgh itself.
- We're mostly interested in information resources.
Examples of Resources

Examples of Resources
http://flickr.com/photos/tags/beltane
Examples of Resources
http://labs.google.com/ridefinder?z=4&near=Washington%2C%20DC&src=1
Examples of Resources
<html xmlns="http://www.w3.org/1999/xhtml">

URIs, URNs, URLs
URIs come in two kinds:
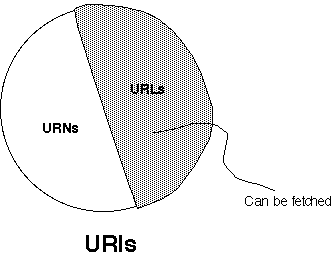
- URNs just name a resource.
- URLs can be used to access a resource.
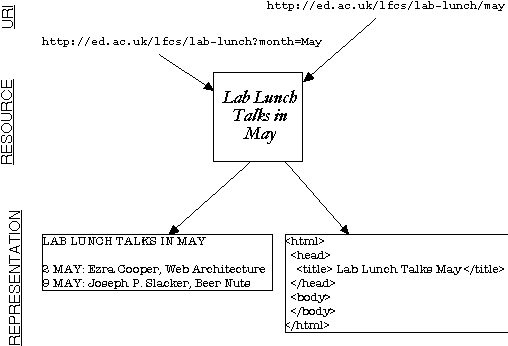
When you access a resource, you get a representation.
Inside a URI
|
http://
|
ed.ac.uk |
/lfcs/lab-lunch |
?month=May |
#web-arch
|
| Scheme |
Authority |
Path |
Query |
Fragment |
Two important properties of a URI:
- Identity: URIs are comparable (byte-for-byte).
- "Authority" component allows delegation of naming authority: no risk of conflicts.
What can I do with a resource?
- Depends on the URI scheme.
- Any number of things, as specified by the resource owner.
- For an
http: URI, you can usually access a representation.
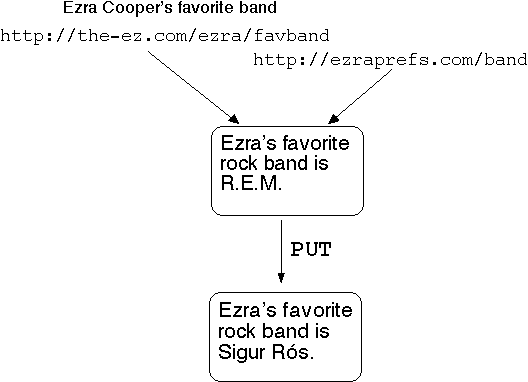
How resources behave
A resource is like a reference cell.
Here's a picture of the resource "Ezra's favorite band." It changes
over time.
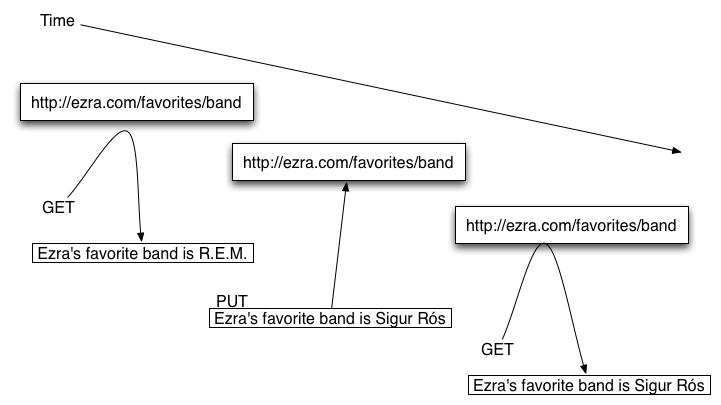
URIs, Resources, Representations
One or more URIs can identify a resource; one resource can have zero
or more representations.
Why URN?
A URN identifies a resource with no representations. Why offer less than one?
Example: City of Edinburgh has no web servers but wants to allow 3rd parties to refer to individual streetlamps.
urn:edinburgh.uk:streetlamp,1456
Lesson:
Making up URIs does not require you to provide
services. URIs are for identification.
Multiple representations
Why offer more than one representation?
- Content negotiation (client and server negotiate a shared
data format: e.g. QuickTime vs. Windows Media).
- Representation can change based on context—e.g.
the person viewing it.
Rep'n can depend on viewer
http://flickr.com/photos/good_day/59673447
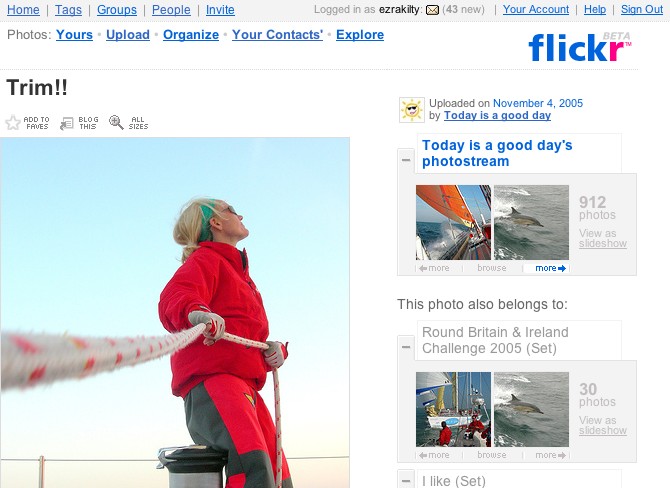
What defines a resource?
A resource is defined by whatever concept its owner wants to use.
-
"The picture of Garth's cat taken just before entering the bath on
October 2, 2005."
-
"Whatever picture of any cat that I feel like offering at a given time."
Relative resources considered harmful
Consider a resource whose definition is relative to the person who's
viewing it, and one that's the same for everyone:
- "The text of the JACM paper the user previously chose to view."
-
"The text of 'Fault-tolerant wait-free shared objects' by Jayanti,
et al."
The former definition breaks when I send the link to my mate.
A resource should be defined by a durable, viewer-independent concept.
Private information should be protected by other means than obscure naming.
How resources behave
Resources can hold the same contents, yet be distinct (like
reference cells).

Distinctness is determined by the resource owner, but generally
follows the URI.
Aliasing of resources
More than one URI can point to the same resource.
This should be avoided, but is sometimes necessary (backward compatibility).
Latest version & dated versions
"The current version" of a paper is a resource of interest, as is "the
version published in such-and-such journal."
"The current value of X" and "The value of X at time T" are
(usually) distinct resources. Assign distinct URIs.
Use this technique for documents that change.

Intermediaries: components that care
Any number of intermediaries can lie between client and server.
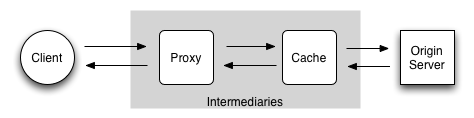
Caches will compare URIs; this is one reason why aliasing is bad.
Besides these discrete network components, there can be other software systems that want to know the identity of a resource.
External services: annotation
-
Offering a good, persistent URL means that external services can
reference and build on your resources:
-
del.icio.us allows people to associate tags with a resource.
-
zBubbles allowed people to annotate a resource with comments,
and browse the web with these comments enabled.
-
In present web-browsers, good URIs are mainly useful for fetching
resources. There are other reasons to assign good URIs...
Verbs: HTTP methods
-
URIs are the nouns of the web.
-
HTTP defines four verbs ("methods"):
GET, PUT, POST,
DELETE. Each can be applied to a URI.
- Loosely-defined semantics:
-
GET returns a representation;
-
DELETE removes the resource;
-
PUT takes the body of the request as a new
(replacement) representation of the resource;
-
POST adds new associated resource,s or changes the resource,
based on the body of the request.
Why use the right method?
HTTP methods show what you're doing so intermediaries
know what you're doing
-
GET requests are safe: they don't entail
obligations on the part of the requester.
-
Conversely, you
should use a
GET request, and thus define a
specific URL, for an operation that is safe.
-
PUT and DELETE requests are idempotent.
You can only take advantage of this if you know whether two URIs identify
the same resource.
APIs: beyond browsing
- Skeptic: "Browsers just
GET resources and sometimes
POST a form. Why all this conceptual machinery?"
APIs: beyond browsing
- Skeptic: "Browsers just
GET resources and sometimes
POST a form.
Why all this conceptual machinery?"
- Because we want to extend the web. Lots of efforts:
- Proprietary APIs: Google Maps API, Mechanical Turk, S3, eBay, etc.
- Standardized HTTP extensions: WebDAV, Atom.
Web APIs: Extending the web
Two principles an API could follow:
- Operation-oriented (SOAP):
- Assign a single URL to the service as a whole.
- Define all the comands that this service supports;
design a format for expressing those commands.
Parse this format from the body of a POST
request to the service URL.
Resource-oriented (REST):
- Assign URLs to all the conceptual resources in your system.
- Let users create, read, update, and delete them using the
standard HTTP methods.
Comparing design principles (SOAP)
- Offers a predefined set of operations. Operations cannot
be extended by smart users.
- Opaque to the rest of the web: intermediaries don't know what's going on.
- Has a straightforward mapping to/from an existing API (e.g.
Java class definition to SOAP WSDL).
Comparing design principles (REST)
- Users can make endless combinations of operations out of the four basic verbs.
- Read-only operations use
GET: intermediaries
can cache these responses and will not repeat an unsafe operation.
- Since resources are visible as URLs,
external software can build data structures around them
(annotating the web).
What if you need more?
- Some protocols conservatively extend HTTP with new verbs:
WebDAV uses
LOCK, PROPFIND and
PROPPATCH.
- But most of what we do on the web is CRUD.
- Even so, some thinking is to be done about how to support
atomic sequences of operations in a REST style.
That's all
☺